与MySQL相比,Hbase首先依赖于HDFS和zookeeper。2,几百亿其实挺多的,hbase的设计必须与您的业务相关,hbase不能完全像关系数据库那样查询,达到一定的数量级,设计不好的话会很慢,甚至hbase会崩溃。如何在hbase中设计更多的行键?基地是按顺序存储在三维空间的,HBase中的数据可以通过三个维度快速定位:行键、列键(列族和限定符)和时间戳。
首先要把关系数据库数据表的数据增加从Hbase数据表的“纵向扩展”改为“横向扩展”。1.HBase的存储结构a)HBase以表的形式存储数据b) HTable包括很多行,每一行都用RowKey唯一标记,并且按照RowKey的字典顺序排列行。将表按行的方向划分为多个HRegionc)每一行包含一个RowKey和多个ColumnFamily,按照column family对数据进行物理切割,即不同column family的数据放在不同的存储中,一个column family放在一个Strore中。d)HRegion由多个商店组成。
2、HBase写性能优化上一篇文章主要介绍了优化HBase阅读性能的基本例程。本文讲述了如何诊断HBase写数据异常问题,优化写性能。与读取相比,HBase中写入数据的过程非常简单:先将数据写入HLog,再写入对应的缓存Memstore。当Memstore中的数据大小达到一定阈值(128M)时,系统会将Memstore中的数据异步刷新到HDFS,形成一个小文件。
这两类问题的切入点也不同,如下图所示:优化原理:数据写过程可以理解为按顺序写一次WAL,写一次cache。通常情况下,写缓存的延迟很低,所以提高写性能的唯一方法就是从WAL入手。WAL机制一方面是为了保证即使写缓存丢失也能恢复数据,另一方面是为了集群之间的异步复制。默认的WAL机制是打开的,WAL是使用同步机制编写的。
3、淘宝为什么使用HBase及如何优化的1前言hbase是从hadoop中分离出来的apache顶级开源项目。因为它用java实现了google的bigtable系统的大部分功能,所以在数据快速增加的今天非常受欢迎。对于淘宝来说,随着市场规模的扩大,产品和技术的发展,业务数据量越来越大,海量数据的高效插入和读取变得越来越重要。因为淘宝拥有或许是国内最大的单个hadoop集群(天梯),对hadoop产品有着深刻的理解,自然希望用hbase来做这样的海量数据读写服务。
2为什么要用hbase?2011年之前,淘宝所有的后台持久化存储基本都是在mysql上进行的(不排除少量的Oracle/BDB/Tail/MongDB等。).mysql因为开源和良好的生态系统,有子数据库、子表等多种解决方案,所以长期以来满足了淘宝大量商家的需求。但是,由于业务的多元化发展,越来越多的业务系统的要求开始发生变化。
4、Hbase读写原理不同的文件夹中存在不同的柱族。与MySQL相比,Hbase首先依赖于HDFS和zookeeper。Zookeeper分享了Hmaster的一些功能。当客户端执行DML语句时,它总是首先与ZK交互。RegionServer管理着很多区域(表),RegionServer中的WAL(HLog)是一个预先写好的日志,它的作用是防止内存中的数据丢失,以及磁盘掉落时丢失。
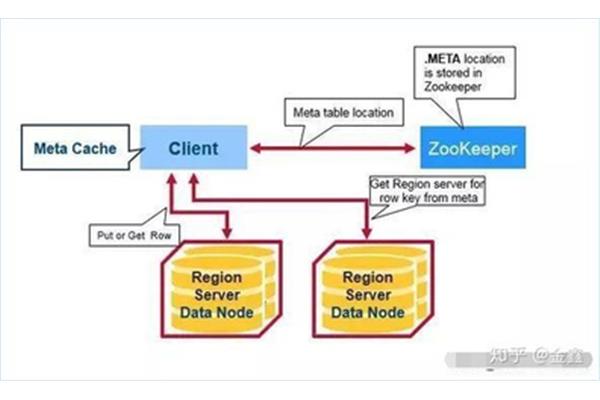
Hbase读取速度比写入速度慢。在Hbase名称空间下有一个张远数据表元表和名称空间表。元表存储元数据,例如要操作的表的位置。(1)首先,客户端向zk请求元数据表所在的RegionServer,zk向客户端返回元表所在的regionServer。
5、hbase行键怎么设计越多越好吗Base是三维有序存储的,HBase中的数据可以通过rowkey、columnkey(columnfamily和qualifier)和TimeStamp三个维度快速定位。RowKey是二进制码流,可以是任意字符串,最大长度为64kb,实际应用中一般为10100字节。用byteHBase实现查询只有两种方式:1。根据指定的行键获取唯一的记录。Get方法(org . Apache . Hadoop . h base . client . get)2。根据指定的条件获取一批记录。扫描方法(org . Apache . Hadoop . h base . client . scan)利用扫描方法实现条件查询功能。使用scan时,值得注意以下几点:1。scan可以通过setCaching和setBatch的方法提高速度(用空间换时间)。2.扫描的范围可以由setStartRow和setEndRow (1。第一,你有这么多服务器集群吗?如果只有几台服务器,如果你想有足够的,你的hbase有几百亿,那么你的hdfs上的数据可能有两个备份。这几百亿是怎么产生的?mapreduce肯定用完了,把它们导入hbase,那么要不要保留原来的数据?如果是,请添加备份。2,几百亿其实挺多的。hbase的设计必须与您的业务相关。hbase不能完全像关系数据库那样查询,达到一定的数量级。设计不好的话会很慢,甚至hbase会崩溃。
6、hbasescan的startRow和endRow拿一个场景来说,安全领域的溯源性分析,查询维度包括ip、时间戳、端口、协议,可能会根据前两个维度中的一个或几个来查询原始日志,我们可以将原始日志存储在hbase中,前述维度可以分别作为key的一部分。首先要考虑rowkey的设置,第一,哈希或反转,以确保数据将随机分布在不同的区域。第二:预分区,先对数据做一个基本的统计,比如我们把数据预先分成十个区域,我们可以统计每个区域的startrow和endrow,这样就可以保证每个区域的数据是等价的。另外,这个好处是当我们根据rowkey查询时,可以保证直接定位到某个分区。

